

This question might be a little out there; nevertheless, I wanted to share my thoughts on this topic. It came to my mind after reading about the connection between the
Even though A/B tests and classification problems are different by nature, they also have something in common. In both situation we are dealing with two groups that should be different with respect to a selected feature. And as it seems now, we are even using equivalent statistics for analyzing both of them, the
The answer might be obvious for you, but if not you should read this blog post. You never know what tricky questions might be waiting for you in your next job interview 
But first things first, let’s briefly recall the definition of ROC curves and some of their properties.
Receiver operating characteristic (ROC) curves are graphical representations of the relationship between the true positive rate (TPR) and the false positive rate (FPR) for all possible threshold values of a binary classifier. They are used to assess the discrimination ability of a classifier and to compare a group of classifiers with each other. Typically, ROC curves are constructed by plotting all (FPR, TPR) points based on the predicted scores on a validation dataset. Afterwards, linear interpolation is applied to connect the points to a curve (see Figure 1 A). This can be seen as a descriptive statistics approach, where only the data at hand is being summarized. On the other side, if we assume the data to be a sample from a population, we can apply statistical inference methods to estimate the real underlying ROC curve (see Figure 1
B). There are many different methods and models described in literature; for a small overview see de Zea Bermudez, Gonçalves, Oliveira & Subtil (2014).
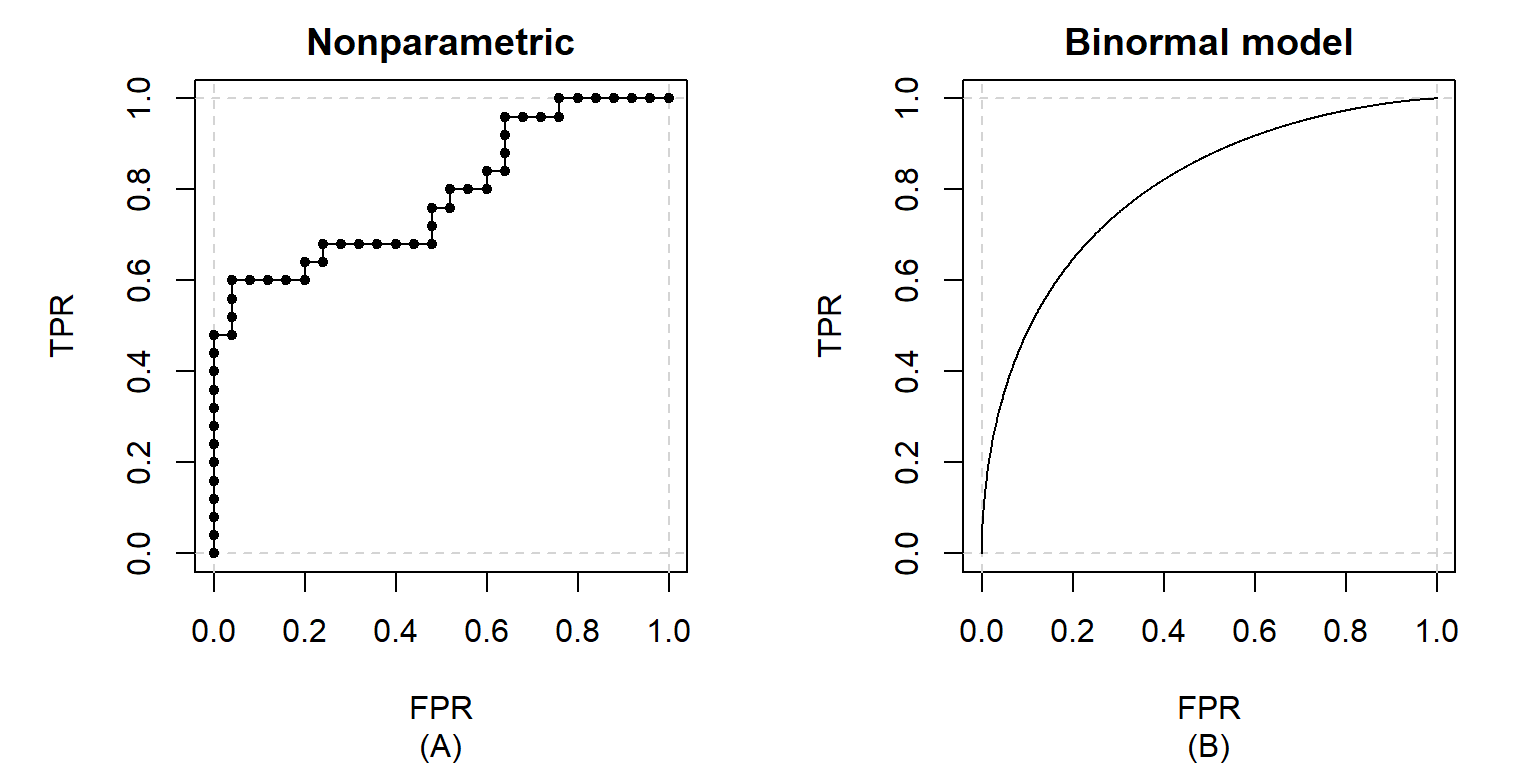
Figure 1: Examples of ROC curve estimates using a nonparametric approach (A) and a binormal model (B)
It’s common practice to use summary measures for comparing ROC curves (curve estimates). The probably most widely used one is the area under the curve (AUC). Let’s assume that the scores assigned by our classification procedure to positive and negative entities are realizations of two continuous random variables
What do ROC curves have in common with the
statistic?
This becomes quite obvious once you have a closer look at the definition of the
where
It’s pretty intuitive that
Does it mean we can use ROC curves for A/B test evaluations?
Not really. We could calculate the ROC curve for an imaginary classifier that would try to assign a user to group A or B based on a selected KPI, but it wouldn’t be very informative for us. The reason for this is that we put emphasis on different things while analyzing A/B tests and when analyzing classifying procedures. In an A/B test our main goal is to assess whether the differences between group A and B are statistically significant, even if they are small; how small they can get and still be business relevant is a different question. When analyzing the performance of a classifier we are checking if the differences are big enough to provide discriminative power.
When testing a new feature on your webpage with an A/B test you probably don’t expect the users behavior to change so drastically that you could make accurate predictions to which group, A or B, a random user belonged, based solely on his behavior. The two probability density functions (PDF) of the measured KPI (a score calculated for each user) from group A and B will be rather “close” to each other. Therefore, the AUC of the estimated ROC curve will be close to 0.5 (see Figure 2). To achieve higher AUC values, the PDFs need to be further “away” from
each other (see Figure 3), which is very unlikely to happen in an A/B test.
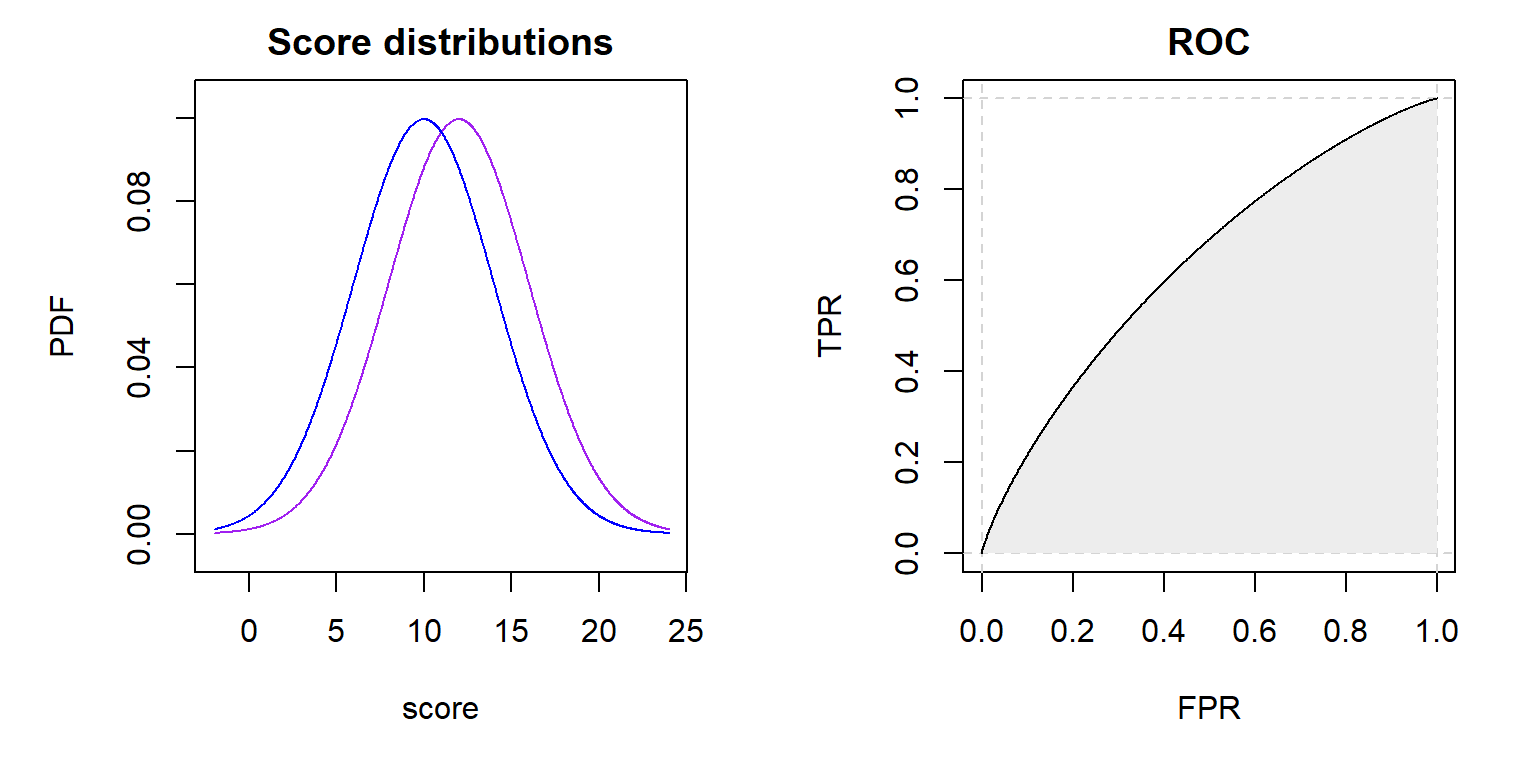
Figure 2: Theoretical PDFs of the scores from positive and negative entities are
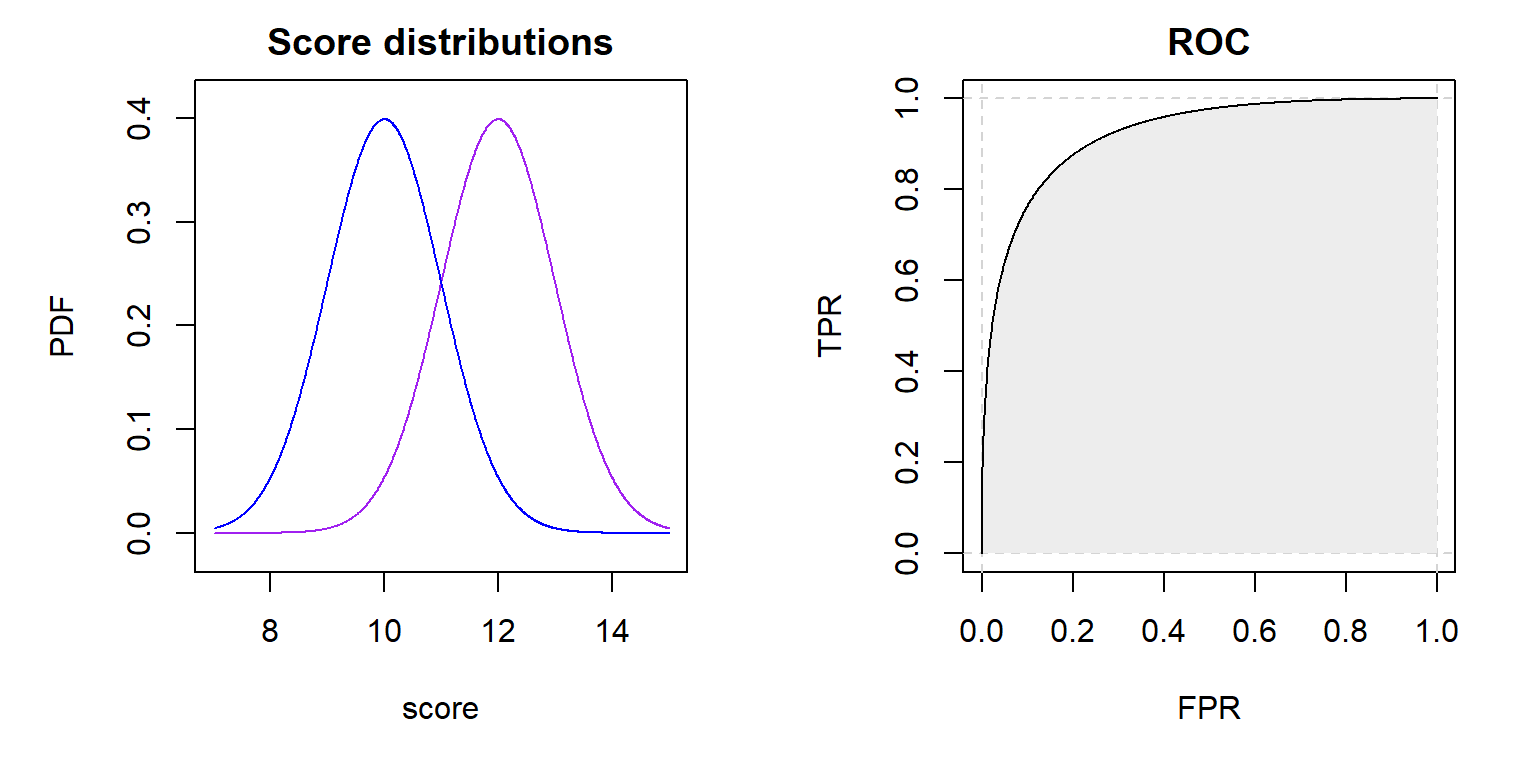
Figure 3: Theoretical PDFs of the scores from positive and negative entities are
How else can we make use of the relationship between the AUC and the
statistic?
A drawback of the Mann-Whitney
Imagine you have a dataset of the following form:
#> clicks user_count group_A group_B
#> 1: 0 905430 453834 451596
#> 2: 1 908886 453605 455281
#> 3: 2 455993 228247 227746
#> 4: 3 151509 75368 76141
#> 5: 4 38192 19021 19171
#> 6: 5 7664 3791 3873
#> 7: 6 1248 596 652
#> 8: 7 190 91 99
#> 9: 8 20 13 7
#> 10: 9 2 1 1You could create a ROC curve out of it, but most importantly you can calculate the AUC and the
prep <- rkt_prep(
scores = data_agg$clicks,
negatives = data_agg$group_A,
positives = data_agg$group_B
)
roc <- rkt_roc(prep)
plot(roc)(AUC <- auc(roc))
#> [1] 0.5009079
(U <- AUC * prep$neg_n * prep$pos_n)
#> [1] 763461645613The p-value can be now derived using a normal approximation. You can write the necessary code by yourself, but you don’t need to. The development version of ROCket available on GitHub already contains a mwu.test function:
# remotes::install_github("da-zar/ROCket")
mwu.test(prep)
#>
#> Mann-Whitney U test
#>
#> data: prep
#> U = 7.6346e+11, p-value = 0.008975
#> alternative hypothesis: two.sidedI hope this article helped you to connect the dots, and now it’s clear why ROC curves are used for classifiers but not for A/B tests. The ROC and AUC serve well the purpose of descriptive statistics, which is enough for some use cases. In A/B tests, though, we need something more sophisticated, namely statistical inference, to perform proper reasoning.
A good understanding of different statistical approaches and how they relate to each other is priceless. There are situations where a different view on a problem can lead to surprising benefits.
Last thing I would like to share is this blog post: Practitioner’s Guide to Statistical Tests. Not only is it a nice guide for choosing the right statistical test for your A/B test, but it also shows by example how to incorporate ROC curves in the estimation of the power of a statistical test.
That’s all for now. I hope you enjoyed reading and found something useful!
Author

This article was written by Daniel Lazar, a Data Scientist at Bonial.


